반응형
1. 명령 창(Command Window) 활성화
Visual Studio에는 명령 창을 통해 다양한 명령어를 실행할 수 있습니다.
- 명령 창 열기:
- 상단 메뉴에서 View(보기) → Other Windows(기타 창) → **Command Window(명령 창)**를 클릭합니다.
- 또는 Ctrl + Alt + A 단축키를 사용합니다.
- 명령 실행:
- 명령 창에서 원하는 명령어를 입력합니다. 예: git blame <파일 경로>.
- 명령 창은 Git 명령을 직접 실행하기보다 Visual Studio 명령을 다룰 수 있습니다. 터미널 기능은 별도로 사용해야 합니다.
2. 통합 터미널 활성화 (Git 명령 실행에 적합)
Visual Studio 2017부터는 통합 터미널(Integrated Terminal)이 없으므로, 외부 명령 실행을 위해 다음을 설정합니다:
- Package Manager Console 사용:
- 메뉴에서 Tools(도구) → NuGet Package Manager → Package Manager Console로 이동합니다.
- Package Manager Console에서 Git 명령어를 실행할 수는 없지만, 관련 패키지 관리 명령어를 사용할 수 있습니다.
- Git Bash 또는 외부 터미널 통합:
- Tools(도구) → **External Tools(외부 도구)**를 클릭합니다.
- **Add(추가)**를 선택하여 아래 내용을 입력합니다:
- Title: Git Bash
- Command: Git Bash 실행 파일 경로 (C:\Program Files\Git\bin\bash.exe 등).
- Arguments: 필요한 경우 추가적인 명령을 설정.
- Initial Directory: $(SolutionDir)로 설정하면 현재 솔루션 디렉터리를 기본 디렉터리로 설정합니다.
- 저장 후, Tools(도구) 메뉴에서 추가한 Git Bash를 선택하여 명령어를 실행합니다.
3. Git 명령어 실행 결과를 Output 창에 표시
Visual Studio 내부에서 Git 명령어 결과를 Output 창에 표시하려면 다음 단계를 따릅니다:
- Git 설치 확인:
- Visual Studio가 Git을 인식할 수 있도록 PC에 Git이 설치되어 있어야 합니다.
- 설치된 Git 경로를 Visual Studio의 환경 변수에 추가합니다.
- Task Runner 설정:
- Visual Studio에서 빌드 작업과 함께 Git 명령을 실행하고, 결과를 Output 창에 출력하도록 설정할 수 있습니다. 이를 위해 별도의 Task Runner를 작성하거나 확장을 설치해야 합니다.
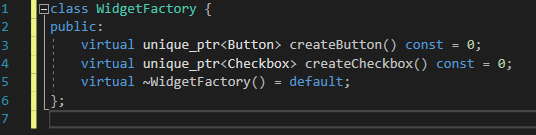
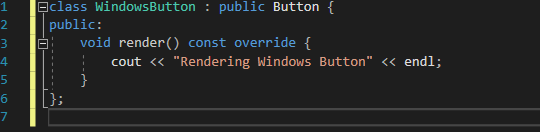
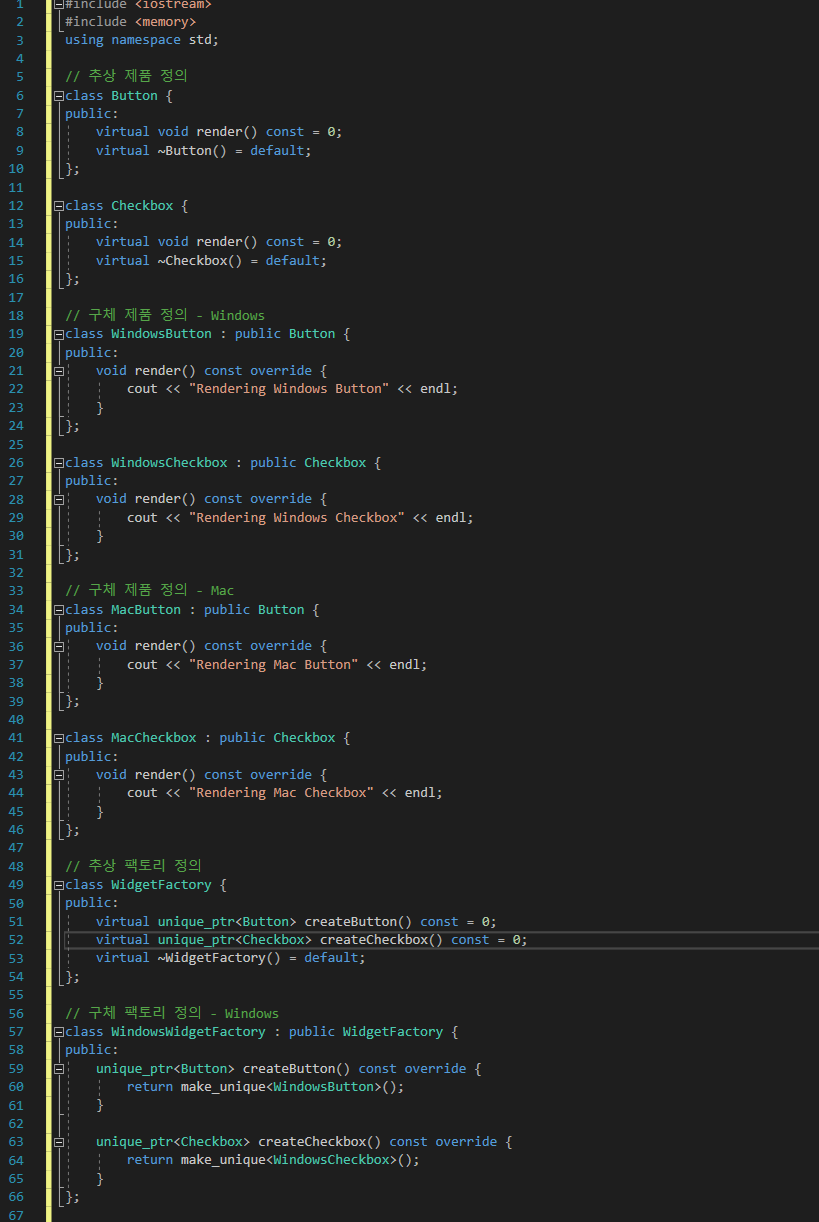
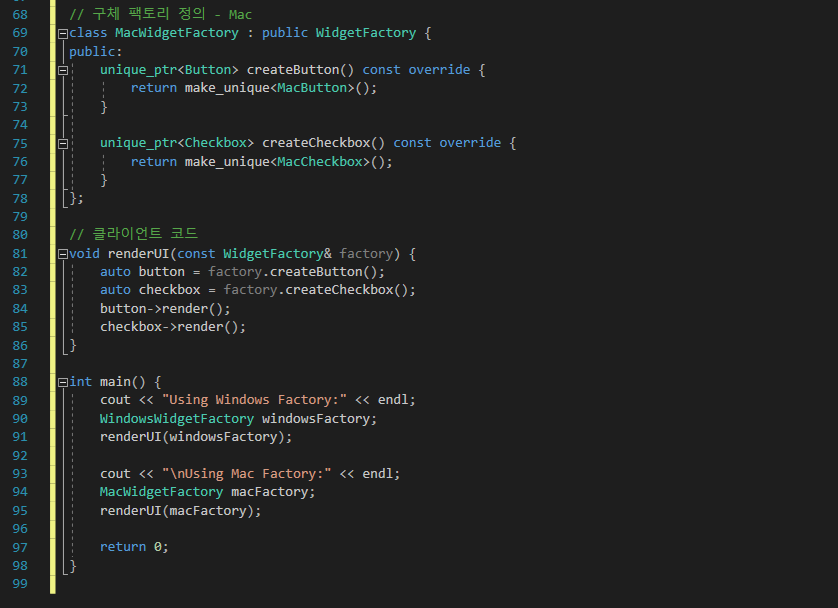
> 하기와 같이 패키지 윈도우를 추가하여 git, window console 명령어를 사용할 수 있다.

'Computer Programming > Tip' 카테고리의 다른 글
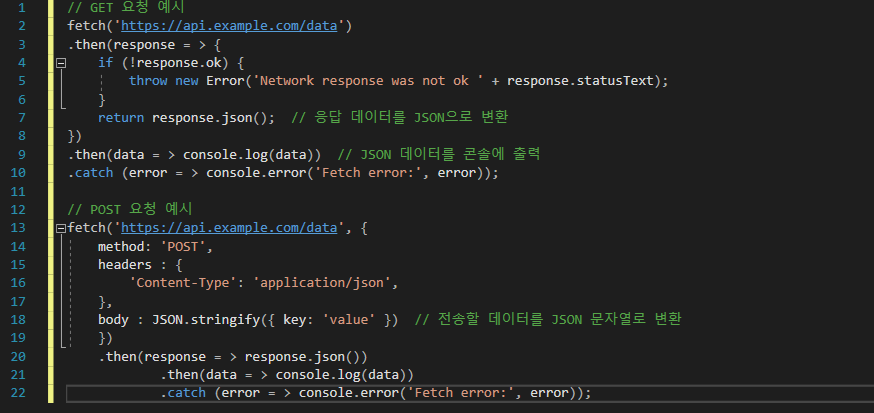
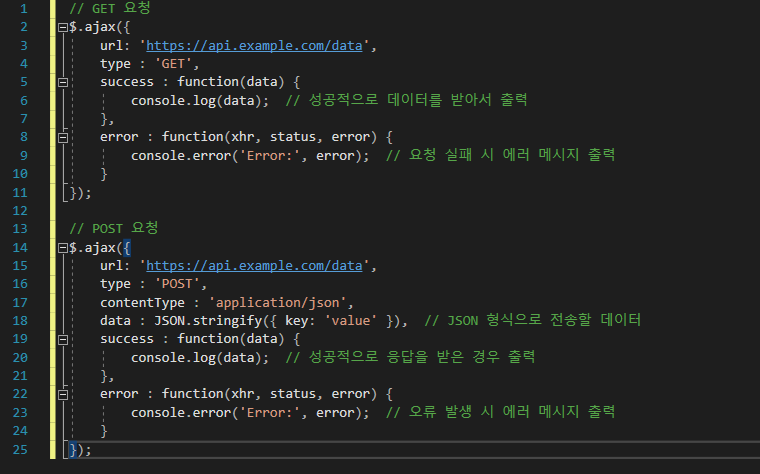
| [HTTP] Get 과 Post 의 요청방식 차이 (0) | 2024.11.11 |
|---|---|
| [Tip] TortoiseGit blame 라인 이동 단축키 (0) | 2020.06.04 |
| [MAC] 마우스 휠 스크롤 방향 (0) | 2016.09.06 |
| [기타] Alt 한글 전환 레지스트리 (0) | 2013.10.28 |